Project Gloves
Projects | | Links: Github | Weights & Biases

This project was for exploring siamese network algorithms along with MLOps technologies.
Links to Weights & Biases metrics
Oxford Pet Classification with different encoders
Training of siamese network with L1 distance layer
Training of siamese network with L2 distance layer
Training of siamese network with cosine distance layer
Training of siamese network with sigmoid head and cross-entropy loss
Oxford Pet Classification with Pretrained siamese encoder base frozen
Oxford Pet Classification with pretrained siamese encoder base unfrozen
Oxford Pet Classification with imagenet base with feature extraction frozen
Oxford Pet Classification with imagenet base with feature extractor unfrozen
The original goal of the project was simple: Create a facial recognition system for my pets.
But it ended up taking many twists and turns and has not yet reached its end goal.
Overview
This project started from the goal of building a facial recognition system for my pets. This was inspired by my desire to learn more about siamese networks and few/one-shot learning. I wanted to be able to pop in any images of a pet and produce a classifier for it instantly. Siamese networks provide a way to do just that.
The name “Project Gloves” was an ommage to one of my cats, Mr. Murder Mittens (pictured above). The name was also inspired by hearing CGPGrey talk about his enjoyment of cryptic project names.
Background on siamese networks
TODO: I leave this part for later. Google will produce enough background on the technology for now.
What this project currently does
This project is split up into various independent stages. I use DVC to drive and glue together the various stages. DVC allows me to cache stages and not rerun them if the designated dependent files do not change. It also serves as an alternative to git-lfs for pushing large files to remote storage. I use minIO as the endpoint for DVC to push my large files to.
DISCLAIMER: I know these stages are not the best way to organize a project. They were built to learning pipelining. In hyperparameter tuning, it all gets recorded to a single project.
Below is a DAG of the project produced by DVC.
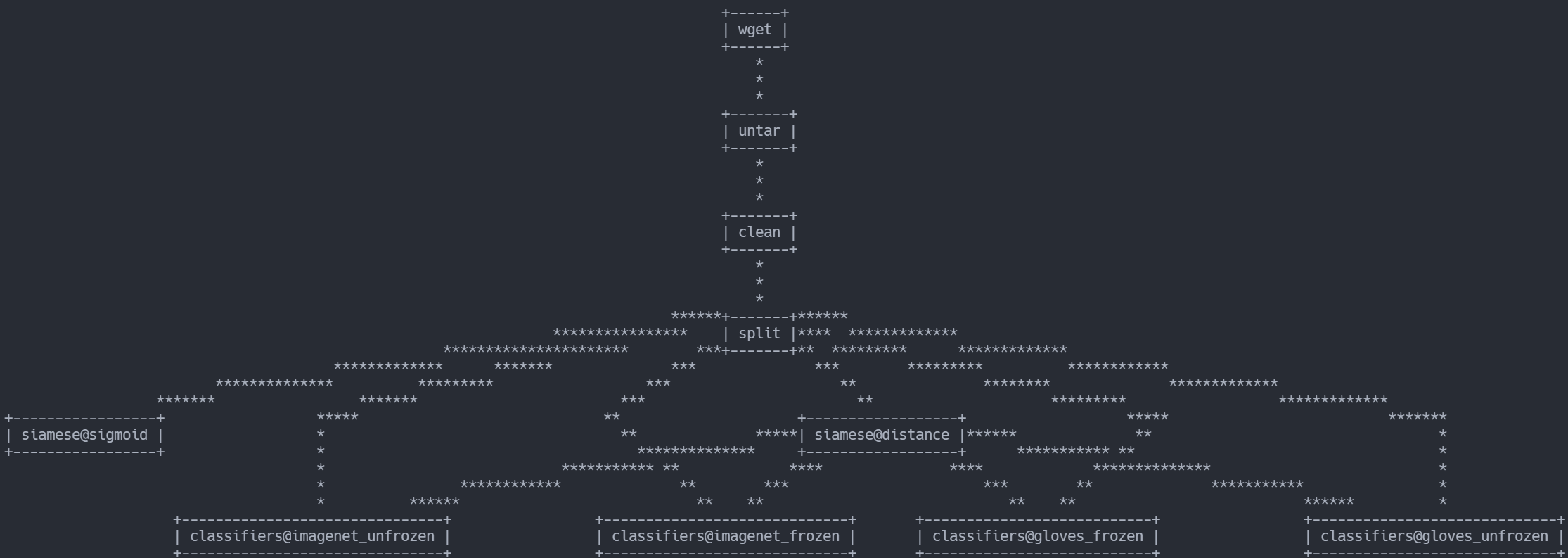
It starts with a wget of the Oxford-IIIT Pet Images dataset from its hosting location. It is then untared. While downloadng and untarnig could have been done in the same step, I was practicing pipeline stages. So I wanted to make more stages.
Data is then split into training and testing sets before flowing to other stages. Looking at the dag now, I see a reason I am beginning to prefer Kedro to DVC for pipelines. I like how in Kedro’s DAGs and graphs, you can see the output of stages rather than only the stages. Examples of Kedro’s DAGs can be seen in my project page on Kedro here The charts I am used to seeing are the product of the kedro-viz package, so maybe DVC supports better visualizations though other means.
The data is used to train multiple versions of models.
One variant of siamese networks uses the typical sigmoid head and cross-entropy loss. This is the typical approach seen in various tutorials. This approach essentially builds a classifier that says “are these two images the same or not”. It fufiles the basic goal of the project. But it just did not feel right.
After reading information on triplet loss, I knew I wanted to go in that direction. However, triplet loss remains a bit out of reach for me to implement just yet. So I went with a simple contrastive loss for the moment.
The other variants of siamese networks use contrastive loss with various distance metrics. It originally just used the L2 distance, but after I learned more about distance metrics in my experiments with auto-encoders (see [here] (/projects/pokegen) for those experiments). I then wanted to see how L1 or cosine distance would perform. Would the down-weighting of magnitudes of cosine distance help or hurt?
So I added variants of the model to be trained with the 2 other distance functions. This was actually a fairly painless process thanks to the DVC infastructure I already put in place. I did have to change an arguement in a few places, but other than that, I simply added an extra parameter in the DVC param.yaml file and DVC automatically created new stages for the metrics.
This was entirely due to how I had structured my DVC configuration. DVC is a great tool, but do not assume it was easy to get my DVC configuration to its current point.
Parameterization
Most parameters for training models can be found and tweaked in params.yaml. Tweaking parameters will register as a change in DVC and will trigger a re-run of the pipeline on the next dvc repro.
Containerization
It should be noted that all stages are run in a Docker container.
Each DVC stage tracks the local files as dependencies for caching purposes. It then mounts those files into the container that will perform the stage. Each container for a stage takes all required arguments and paths as command line arguments when it is run.
Some stages have all the necessary files in the container. Training stages use a image with just the dependencies installed then mount the current code into the container. The training image does have the code mounted inside it, but this code is overwritten during stage execution by DVC. This is because the code changes a lot when experimenting, and I did not want to have to keep rebuilding images.
This was a relic how the project used to run in Kubeflow Pipelines at one time. I kept this functionality when moving back to DVC as it provided a interesting challenge. I wanted to see if I could mimic Kubeflow Pipelines in DVC. This would also allow me to go back to Kubeflow Pipelines in the future if I wanted to.
I would also be lying if I did not say I mostly kept the containers approach around because it was cool approach and provided an interesting challange to get it working with DVC.
Sidetracks
This project mostly ended up severing as a testbed for various technologies (mostly MLOps tools).
Below are a few of the sidetracks.
Weights & Biases
This was one of the first projects I tracked using Weights & Biases logging platform. It worked great! And I eventually came back to it so I could share my project metrics publicly. See top of this page for links.
MLFlow
I would eventually migrate metric and model logging to MLFlow due to the self hosting capabilities of MLFlow. Through self hosting, I could store as many models as I wanted! I could also make use of MLFlow’s model registry to control to flow of models to production. WandB may have a similar feature to MLFlow Model Registry at this point, but I don’t see a need for switching to anything else for this project.
While I still track metrics and models in MLFlow, it’s metric tracking is mirrored in Weights & Biases.
I use MLFlow’s model registy to pull models for demo sites that use them.
Kubeflow
This was one of the first projects I adapted for Kubeflow. This was at a rare point in time where the Kubeflow installation was still possible in one attempt.
See here for my experience with Kubeflow. Spoiler alert, it was not positive.
Since then, I have not been able to get a working version of Kubeflow While I love the idea of Kubeflow and Kubeflow Pipelines, it does not appear to be worth using for me in my personal experiments at this point. I see the value in it, but it requires too much time to get up and running.
Mixed Precision
This project spanned me getting my first mixed precision capable GPU to getting one that nearly obsoletes mixed precision.
I tweaked a lot of stuff in this project to get mixed precision working. Now, when I enable it, the code throws warnings for “deprecation”. I have no plans to fix those. I plan to disable mixed precision going forward (not just in this project but all my projects). It provided a nice challenge to explore, made my models smaller, and made them faster.
With my new GPUs supporting TF32 operations, I cannot see any reason to keep using mixed precision in my experiments. It takes too much finessing to get working.
TF32 supposedly provides most of the same benefits as mixed precision with literally none of the hassle. The ability to have those benefits with zero code changes provides too much convenience and flexibility. No more wondering if I missed some black magic element that increases performance of mixed precision. No more having my mixed precision models brick CPU performance on inference. It is just not worth the trouble for me.
Various Issues
I let tensorflow do the caching of the nway dataset. That appears to have been a mistake. It tried putting the whole thing in RAM leading to 50GB to 100GB RAM requirement. This SLAMMED the cache of some of my machines. I eventually gave up and reduced the nway from 32 to 24. This gives me less accurate testing, but significantly reduced the RAM requirement.
Gripes
Too many duplicates of data. Could not cache the data. I guess if the process is consistent (name for this) then it should be ez reproducable. I’m not sure my pipelines are consistent. They should be, but I”m not confident I’m also too lazy to fully verify. Yes, i know it wouldn’t be that hard.
Future Work
I want to implement triplet loss to see how it performs.
I want to get the networks running on embedded hardware (like a jetson nano or pi).
I want to add some optimization steps to the project to trim down the network and optimize it for inference on a chosen embedded hardware platform (e.g., pruning, quantization, etc.). This would also be a good chance to explore TensorRT.
I want the GUI’s to not pull the models directly. I want them to simply hit an API endpoint that hosts the models. While I’ve built this numerous times, I didn’t want to rebuild the GUI’s just yet.
Explore benchmarking models with mixed precision vs TF32.
Explore weighting based on label frequency. There’s a slight imbalance in normal labels. Adding my own pets in as categories added significantly more imbalance.
Technologies Used
- Tensorflow / Keras
- Docker
- Kubeflow
